mysql|全表扫描问题
全表扫描流程
InnoDB 的数据是保存在主键索引上的,所以全表扫描实际上是直接扫描表 t 的主键索引。这条查询语句由于没有其他的判断条件,所以查到的每一行都可以直接放到结果集里面,然后返回给客户端。
那么,这个“结果集”存在哪里呢?实际上,服务端并不需要保存一个完整的结果集。取数据和发数据的流程是这样的:
- 获取一行,写到
net_buffer中。这块内存的大小是由参数net_buffer_length定义的,默认是 16k。 - 重复获取行,直到
net_buffer写满,调用网络接口发出去。 - 如果发送成功,就清空
net_buffer,然后继续取下一行,并写入net_buffer。 - 如果发送函数返回 EAGAIN 或 WSAEWOULDBLOCK,就表示本地网络栈(socket send buffer)写满了,进入等待。直到网络栈重新可写,再继续发送。
存在问题
通过上面的流程,可以发现,MySQL 是“边读边发的”,这个概念很重要。这就意味着,如果客户端接收得慢,会导致 MySQL 服务端由于结果发不出去,这个事务的执行时间变长。
如果客户端使用–quick参数,会使用mysql_use_result方法。这个方法是读一行处理一行。因此可以想象一下,假设有一个业务的逻辑比较复杂,每读一行数据以后要处理的逻辑如果很慢,就会导致客户端要过很久才会去取下一行数据,可能就会出现服务端阻塞的现象。
因此,对于正常的线上业务来说,如果一个查询的返回结果不会很多的话,建议使用mysql_store_result这个接口,直接把查询结果保存到本地内存。
InnoDB的buffer poll的LRU算法
基本LRU流程
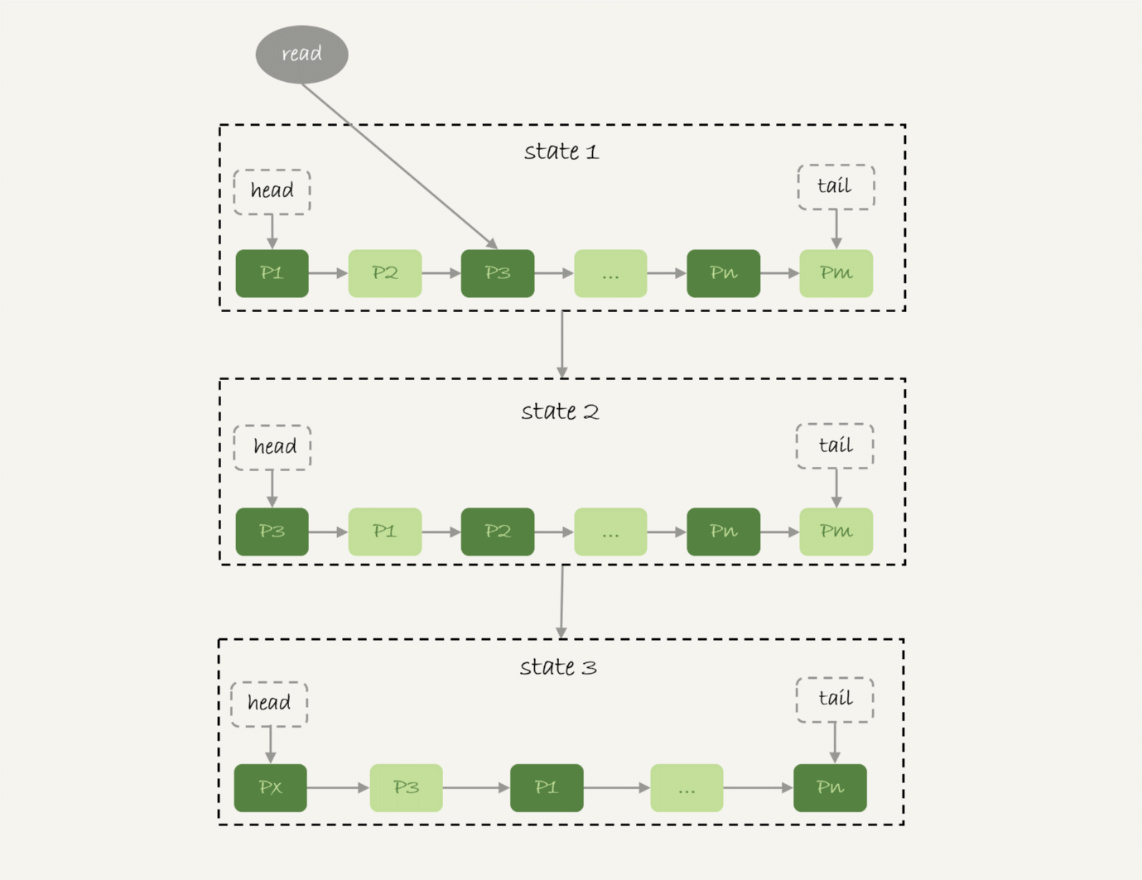
InnoDB 管理 Buffer Pool 的 LRU 算法,是用链表来实现的。
- 在图中的状态 1 里,链表头部是 P1,表示 P1 是最近刚刚被访问过的数据页;假设内存里只能放下这么多数据页;
- 这时候有一个读请求访问 P3,因此变成状态 2,P3 被移到最前面;
- 状态 3 表示,这次访问的数据页是不存在于链表中的,所以需要在 Buffer Pool 中新申请一个数据页 Px,加到链表头部。但是由于内存已经满了,不能申请新的内存。于是,会清空链表末尾 Pm 这个数据页的内存,存入 Px 的内容,然后放到链表头部。
- 从效果上看,就是最久没有被访问的数据页 Pm,被淘汰了。
问题
假设按照这个算法,我们要扫描一个 200G 的表,而这个表是一个历史数据表,平时没有业务访问它。那么,按照这个算法扫描的话,就会把当前的 Buffer Pool 里的数据全部淘汰掉,存入扫描过程中访问到的数据页的内容。也就是说 Buffer Pool 里面主要放的是这个历史数据表的数据。
对于一个正在做业务服务的库,这可不妙。你会看到,Buffer Pool 的内存命中率急剧下降,磁盘压力增加,SQL 语句响应变慢。
改进LRU流程

- 图中状态 1,要访问数据页 P3,由于 P3 在 young 区域,因此和优化前的 LRU 算法一样,将其移到链表头部,变成状态 2。
- 之后要访问一个新的不存在于当前链表的数据页,这时候依然是淘汰掉数据页 Pm,但是新插入的数据页 Px,是放在 LRU_old 处。
- 处于 old 区域的数据页,每次被访问的时候都要做下面这个判断:
- 若这个数据页在 LRU 链表中存在的时间超过了 1 秒,就把它移动到链表头部;
- 如果这个数据页在 LRU 链表中存在的时间短于 1 秒,位置保持不变。1 秒这个时间,是由参数 innodb_old_blocks_time 控制的。其默认值是 1000,单位毫秒。
这个策略,就是为了处理类似全表扫描的操作量身定制的。还是以刚刚的扫描 200G 的历史数据表为例,我们看看改进后的 LRU 算法的操作逻辑:
- 扫描过程中,需要新插入的数据页,都被放到 old 区域 ;
- 一个数据页里面有多条记录,这个数据页会被多次访问到,但由于是顺序扫描,这个数据页第一次被访问和最后一次被访问的时间间隔不会超过 1 秒,因此还是会被保留在 old 区域;
- 再继续扫描后续的数据,之前的这个数据页之后也不会再被访问到,于是始终没有机会移到链表头部(也就是 young 区域),很快就会被淘汰出去。
可以看到,这个策略最大的收益,就是在扫描这个大表的过程中,虽然也用到了 Buffer Pool,但是对 young 区域完全没有影响,从而保证了 Buffer Pool 响应正常业务的查询命中率。